Dieser Artikel beschäftigt sich mit dem Aufbau eines generischen ELT Prozesses mit Talend zur Integration eines Quellsystems in ein Data Warehouse. Generisch bedeutet in diesem Fall, dass keine konkreten Implementierungsdetails wie z.B. Tabellen oder Spaltennamen verwendet werden und die vorgestellte Methodik somit für jedes relationale DB-Schema Anwendung finden kann.
Eine Besonderheit in diesem Artikel ist, dass im Quellsystem kein Delta bestimmt werden kann aufgrund von fehlender Audit Informationen. Diese sind in der Regel als Zeitstempel pro Tabelle festgehalten und geben an, wann ein Record erstellt, gelöscht oder zuletzt geändert wurde. Eine Deltabestimmung berücksichtigt diese Informationen und extrahiert nur Daten, die seit der letzten Extraktion geändert wurden. Fehlen diese Informationen, muss bei jeder Extraktion der gesamte Datenbestand geladen werden.
Hinweis:
Abhängig vom konkreten Anwendungsfall kann bei dieser ELT-Methode eine sehr große Datenmenge im Extract anfallen, tendenziell wird diese über die Zeit größer, somit wird der Integrationsprozess immer länger dauern und kann an seine Grenzen stoßen.
Daher sollte immer abgewogen werden, ob im Quellsystem die entsprechenden Auditinformationen eingebracht werden können/müssen. In jedem Fall kann die vorgestellte Methode schnell implementiert werden und eine Integration des Quellsystems sicherstellen.
Anforderungen
- Quellsystem ist eine Oracle Datenbank
- Integrationssystem ist eine MySql Datenbank
- Beliebiges Quelldatenmodell (QDM) kann verarbeitet werden
- Das Integrationsdatenmodell (IDM) ist eine historisierte Version des QDM: Im QDM gelöschte Datensätze können im IDM abgefragt werden.
- Alle Tabellen des QDM sind mit gleichem Namen im IDM wiederzufinden (es werden keine anderen DB Objekte wie z.B. Views berücksichtigt)
- Alle Columns einer Tabelle im QDM sind mit gleichem Namen und Typ im IDM wiederzufinden (zusätzliche Spalten im IDM sind vorgesehen)
- Das IDM enthält Auditinformationen für jeden Record einer Tabelle (Zeitstempel “Erstellt”, “Letzte Änderung” und “Gelöscht”)
- Der ELT-Prozess toleriert das Wegfallen von Spalten im QDM, kein manuelles Eingreifen ist erforderlich
- Der ELT-Prozess übernimmt neue Columns einer Tabelle aus dem QDM automatisch in das IDM, kein manuelles Eingreifen ist erforderlich
Der ELT Prozess im Überblick
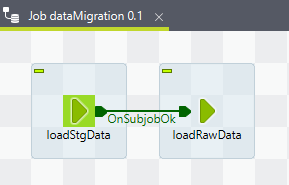
Der Prozess teilt sich auf 2 Teilprozesse auf oberste Ebene auf.
- loadStgData: Extrahiert alle Daten aus QDM und importiert sie in das Staging Schema. Im Staging Schema befindet sich nach dem Extrahieren eine 1:1 Kopie des QDM mit allen Daten.
- loadRawData: Analysiert das Staging Schema, passt das Raw Schema an, importiert die relevanten Daten (das Delta zwischen Staging und Raw Schema) und reichert die Auditinformationen an.
Laden des Staging Schemas
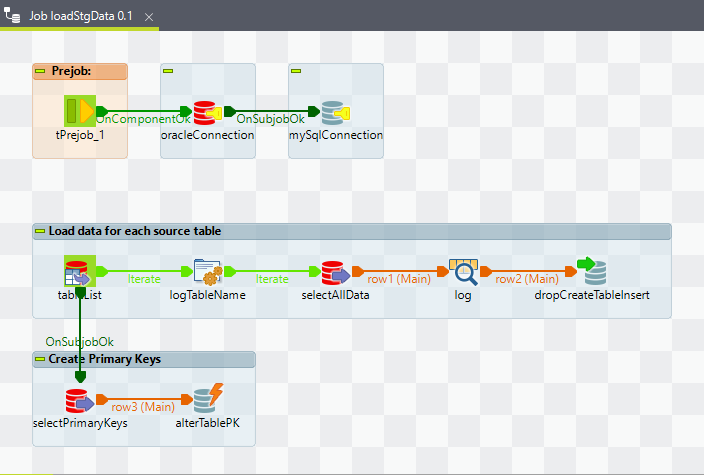
Dieser Job kopiert alle Daten aus dem QDM in das Staging Schema, dabei werden die Tabellen im Staging Schema on-the-fly erstellt bzw. erst gedropped wenn sie schon existieren und dann neu erstellt. Das Schema wird also sozusagen bei jedem Durchlauf komplett neu aufgebaut.
Die einzigen Constraints, die aus dem QDM übernommen werden, sind die Primary Keys. Alle anderen Constraints werden ignoriert.
Im Folgenden werden die einzelnen Subjobs und Konfigurationen der einzelnen Komponenten erläutet. Für den Ablauf nicht funktionale Komponenten wie z.B. Logs werden ausgelassen.
Job Vorbereitung
Als erstes werden 2 DB Connections initialisiert
- oracleConnection: Verbindung zum Quellsystem
- mySqlConnection: Verbindung zum Integrationssystem
Die Konfigurationen sind im Repository hinterlegt. Die Default-Schemata sind ebenfalls in der Konfiguration hinterlegt, sodass kein Schema Name in SQL Queries angegeben werden muss.
Laden der Quelltabellen
Es werdem alle Tabellen des QDM und deren Daten in das Staging Schema kopiert.
Die Tabellen werden dabei on-the-fly erstellt. Besser gesagt, sie werden erst gedropped falls sie schon existieren und dann erneut angelegt.
tableList
Eine Komponente tDBTableList wird verwendet, um die Tabellen innerhalb des QDM zu iterieren.
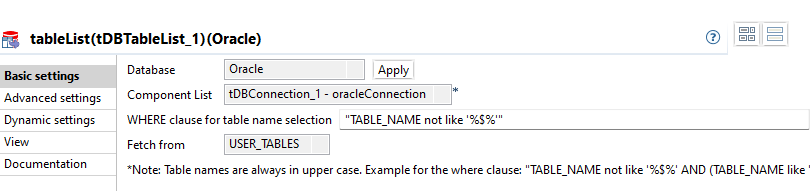
In diesem Beispiel ist der Oracle Owner des relevanten Schemas gleichzeitig in der DB Connection Konfiguration verwendet. Daher kann Fetch from auf USER_TABLES eingestellt werden und WHERE clause for table name selection braucht keine weitere Einschränkung, sodass der Default Wert beibehalten werden kann.
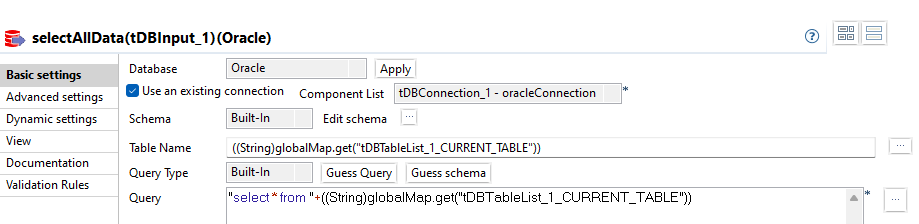
selectAllData
Für jede Iteration (weitere Tabelle) werden alle Records der aktuellen Tabelle geladen.
Das SQL Query verwendet die *-Selektion, um alle vorhanden Columns zu selektieren. Der Tabellenname wird aus der Komponente tableList bezogen: ((String)globalMap.get("tDBTableList_1_CURRENT_TABLE"))
Das Schema des Flows muss so konfiguriert werden, dass es dynamisch geladen wird.
Dazu wird im Schema genau eine Column definiert, deren Type auf Dynamic eingestellt ist. Relevant sind alleine die Attribute Column und Type.
Die Konfiguration veranlasst Talend, das Schema und die Werte zur Laufzeit zu bestimmen und in der Column data zu speichern.
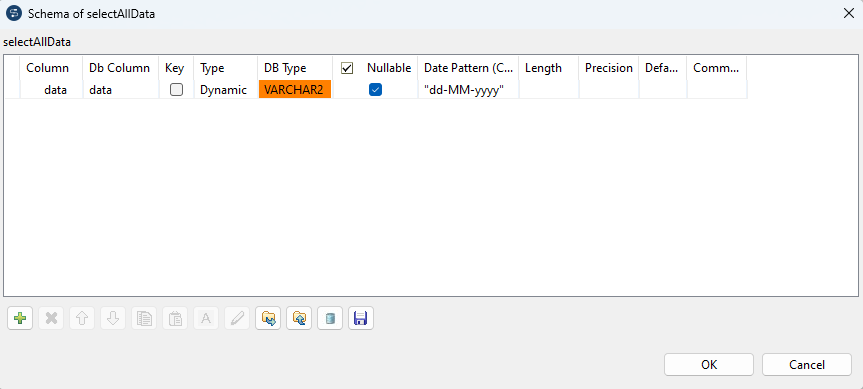
setNullable
Das zuvor beschriebene Dynamic Schema beinhaltet auch Column Informationen über NOT NULL Contraints. Diese werden beim Laden aus dem QDM übernommen und würden ebenso im Staging Schema angelegt werden.
Für alle Columns, ausgenommen diejenigen im Primary Key, wird das NOT NULL Constraint verworfen und stattdessen alle Columns als Nullable angelegt. Der Hintergrund dafür ist, dass die Übernahme der Constraints keinen Mehrwert für die Datenqualität im Staging Schema bietet, da sie nicht mehr bearbeited werden, sondern ausschließlich aus dem QDM kopiert werden. Andererseits könnten Änderungen im QDM an diesem Constraint Auswirkungen haben, falls die Constraints in das IDM übernommen werden. An späterer Stelle wird auf diesen Umstand noch einmal genauer eingegangen.
Hinweis
In diesem Schritt wird tatsächlich jede Column als Nullable definiert und die Tabelle wird zunächst auch so angelegt. Ebenso werden die Daten aus dem QDM importiert, bevor Constraints angelegt werden.
Dies ändert sich im nächsten Subjob, in dem die PKs erstellt werden.
Funktional macht es keinen Unterschied, ob in diesem Schritt die Contraints vorhanden sind, da das QDM die Constraints einhält. Zudem beschleunigt der Umstand der fehlenden Constraints den Import Prozess im Staging Schema, da keine Checks für Constraints durchgeführt werden müssen.
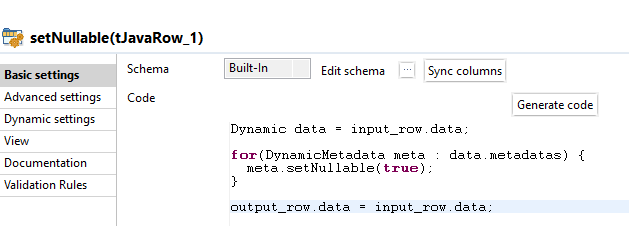
dropCreateTableInsert
Wie bereits erwähnt, wird das Staging Schema bei jedem Integrationslauf komplett neu erstellt. In der Komponente tDBOutput kann in Action on table konfiguriert werden, dass eine vorhandene Tabelle gelöscht und neu erstellt wird, indem der Wert auf Drop table if exists and create eingestellt wird.
Da jede Tabelle neu erstellt wird und somit leer ist, werden einfach alle Daten hinzugefügt. Als Action on data wird der Wert Insert eingestellt.
Das Built-In Schema ist dasselbe wie bei der Komponente selectAllData und wird einfach durch die Schema Propagation übernommen.
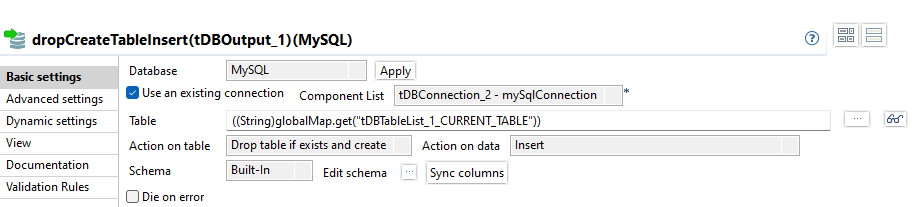
Erstellen der Primary Keys
Für den weiteren Datenintegrationsprozess ist es erforderlich, die Primary Keys für die Tabellen im Staging Schema zu erzeugen, um später das Delta zu bestimmen.
Die benötigten Informationen über die Columns und deren Reihenfolge im Primary Key werden aus entsprechenden Tabellen in Oracle selektiert.
Für jede Tabelle im Staging Schema wird dann ein Primary Key mit den selektierten PK Informationen aus der Oracle DB erstellt.
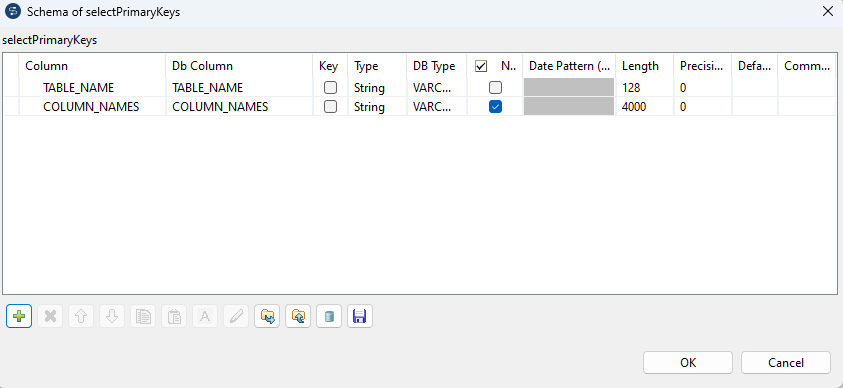
selectPrimaryKeys
Der Subjob beginnt mit einem tDBInput, der für jede Tabelle eine Row erzeugt.
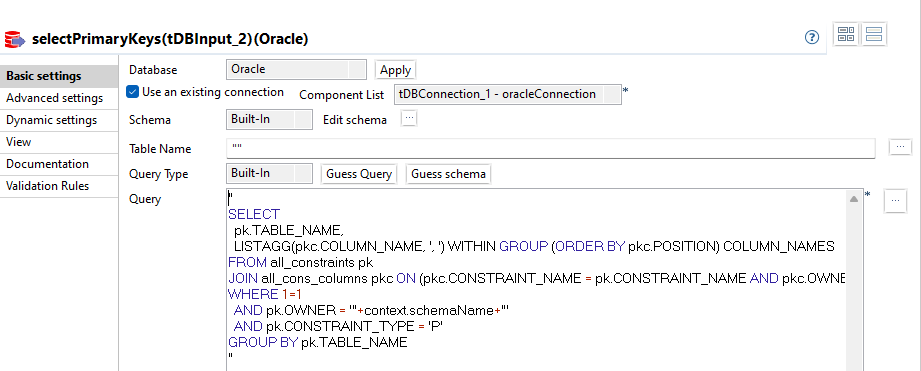
Das Schema beinhaltet 2 Columns.
- TABLE_NAME
- COLUMN_NAMES
Die Primary Key Informationen können in Oracle DB aus den Tabellen ALL_CONSTRAINTS und ALL_CONS_COLUMNS selektiert werden.
Mit folgendem SQL wird pro Tabelle ein Record erzeugt, der den Tabellennamen enthält und eine Komma-spearierte Liste mit den zum PK gehörigen Column Namen unter Berücksichtigung der Reihenfolge wie sie im PK in Oracle definiert sind.
"
SELECT
pk.TABLE_NAME,
LISTAGG(pkc.COLUMN_NAME, ', ') WITHIN GROUP (ORDER BY pkc.POSITION) COLUMN_NAMES
FROM all_constraints pk
JOIN all_cons_columns pkc ON (pkc.CONSTRAINT_NAME = pk.CONSTRAINT_NAME AND pkc.OWNER = pk.OWNER)
WHERE 1=1
AND pk.OWNER = '"+context.schemaName+"'
AND pk.CONSTRAINT_TYPE = 'P'
GROUP BY pk.TABLE_NAME
"Laden des Raw Schemas
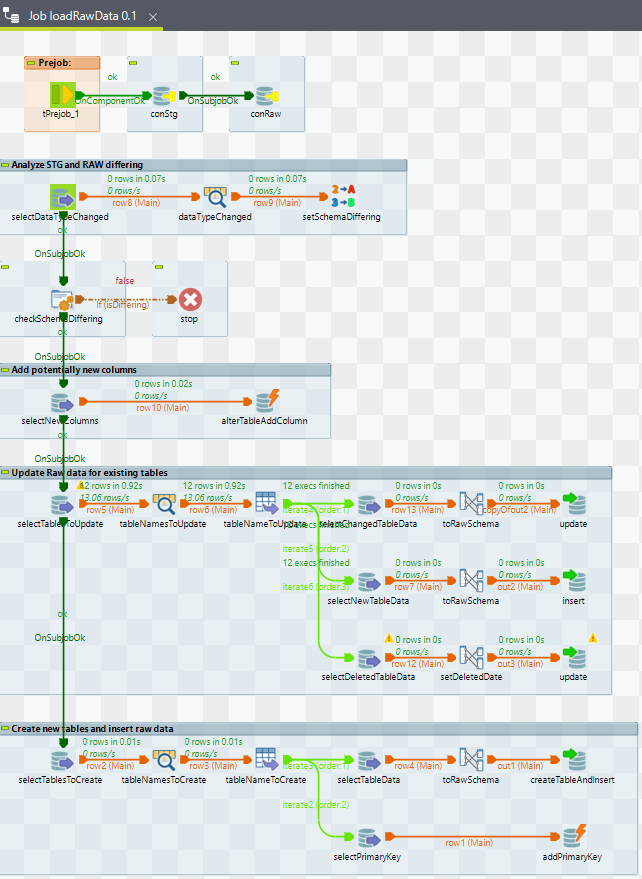
Dieser Job berechnet im Wesentlichen das Delta zwischen Staging und Raw Schema und läd diese neuen Daten in das Raw Schema. Dabei werden auch Änderungen im Schema berücksichtigt.
Da beim Laden des Staging Schemas einfach das gesamte QDM kopiert wird, können Unterscheide zwischen Staging und Raw Schema entstehen:
- Column in einer Tabelle ist neu
- Column in einer Tabelle ist gelöscht
- Column in einer Tabelle hat anderen Datentyp
Die ersten beiden Fälle werden als problemlos betrachtet:
- Gibt es eine neue Column in einer Tabelle, wird im Raw Schema ebenfalls eine neue Column in der korrespondierenden Tabelle erstellt
- Fällt eine Column in einer Tabelle weg, bleibt diese im Raw Schema einfach erhalten und wird bei neuen Records mit NULL belegt.
Bei beiden Fällen wird deutlich, warum die NOT NULL Constraints aus dem QDM nicht übernommen werden.
Würde eine neue Column mit NOT NULL angelegt werden, würde dies zu einer Constraint Violation für alle Datensätze führen, die bereits als gelöscht im IDM enthalten sind. Diese würden nicht mit aktualisierten Werten aus dem QDM importiert werden und müssten aufgrund der technischen Anforderung NOT NULL mit einem Default-Wert belegt werden.
Eine im QDM wegfallende Column, die zuvor als NOT NULL definiert war, würde eine Anpassung im IDM erfordern. Neu Datensätze im IDM hätten keinen Wert für die entfallene Column und würden automatisch mit NULL belegt werden, was wiederum zu einer Constraint Violation führen würde.
Der letzte Fall kann zu einer Inkompatibilität führen:
- Ändert sich der Datentyp einer Column, kann eine Transformation notwendig sein. Ohne genaue Kenntnisse zu dem QDM kann diese nicht durchgeführt werden. Änderungen bezüglich der Länge von Feldern könnten hier auch automatisch umgesetzt werden, solange sie größer werden. Zur Vereinfachung des Prozesses wird jede Datentypänderung als Abweichung, die manuell behandelt werden muss, betrachtet.
Job Vorbereitung
Als erstes werden 2 DB Connections initialisiert:
- conStg: für das Staging Schema
- conRaw: dür das Raw Schema
Beide Konfigurationen beinhalten auch schon das korrekte Datenbankschema, dadurch müssen keine vollqualifizierten Namen in den SQL eingetragen werden.
Abgleich der Schemata Staging und Raw
Wie bereits beschrieben, wird die Abweichung des Datentyps einer Column als einzige Inkompatibilität betrachtet. Der Abgleich der Datentypen erfolgt mit Hilfe des INFORMATION_SCHEMA, sobald es nur eine abweichende Column gibt, wird das gesamte Staging Schema als abweichend betrachtet.
selectDataTypeChanged
Die relevanten Informationen befinden sich in den Tabellen INFORMATION_SCHEMA.TABLES und INFORMATION_SCHEMA.COLUMNS. Verglichen wirden die Werte für COLUMNS.COLUMN_TYPE.
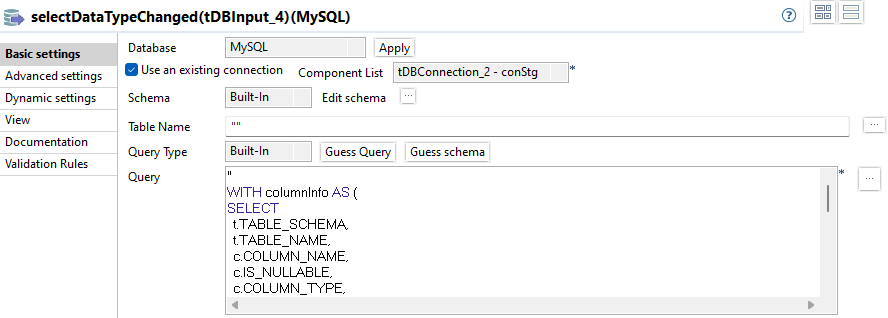
"
WITH columnInfo AS (
SELECT
t.TABLE_SCHEMA,
t.TABLE_NAME,
c.COLUMN_NAME,
c.IS_NULLABLE,
c.COLUMN_TYPE,
c.ORDINAL_POSITION
FROM INFORMATION_SCHEMA.TABLES t
JOIN INFORMATION_SCHEMA.COLUMNS c ON (c.TABLE_SCHEMA = t.TABLE_SCHEMA AND c.TABLE_NAME = t.TABLE_NAME)
)
SELECT
stg.TABLE_NAME TABLE_NAME_STG,
stg.COLUMN_NAME COLUMN_NAME_STG,
stg.COLUMN_TYPE COLUMN_TYPE_STG,
raw.TABLE_NAME TABLE_NAME_RAW,
raw.COLUMN_NAME COLUMN_NAME_RAW,
raw.COLUMN_TYPE COLUMN_TYPE_RAW
FROM columnInfo stg
JOIN columnInfo raw ON (raw.TABLE_NAME = stg.TABLE_NAME AND raw.COLUMN_NAME = stg.COLUMN_NAME AND raw.TABLE_SCHEMA = '"+context.schemaNameRaw+"')
WHERE 1=1
AND stg.TABLE_SCHEMA = '"+context.schemaNameStg+"'
AND raw.COLUMN_TYPE <> stg.COLUMN_TYPE
ORDER BY stg.TABLE_NAME ASC, stg.ORDINAL_POSITION ASC
"Das Flow-Schema lautet wie folgt.
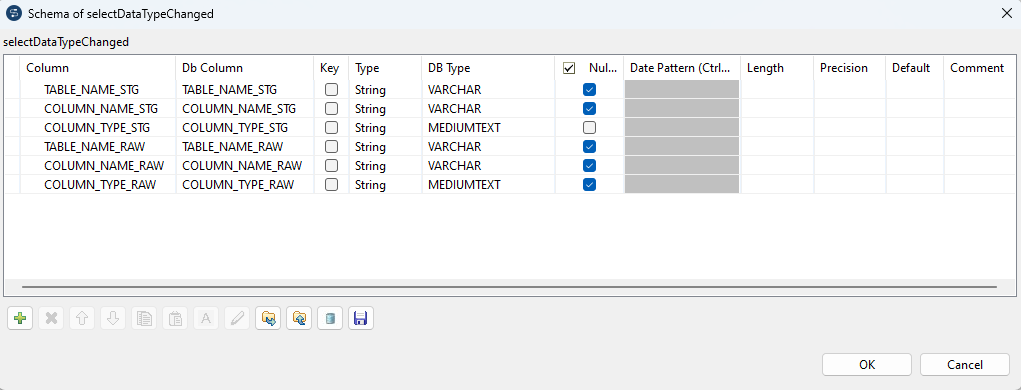
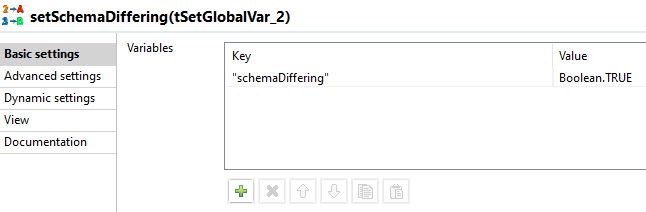
setSchemaDiffering
Die Abweichung wird durch das Setzen der globale Variable schemaDiffering gespeichert.
Abbruch bei abweichendem Schema
Die globale Variable schemaDiffering wird überprüft. Wurde eine Schemaabweichung festgestellt, wurde der Wert auf TRUE gesetzt. Sollte dies der Fall sein, wird der Prozess mit einem Fehler beendet.
checkSchemaDiffering
Die tJava Komponente an sich enthält keinen funktionalen Code. Allein der if-Trigger isDiffering enthält die Prüfung der globalen Variablen:

stop

Hinzufügen neuer Columns
selectNewColumns
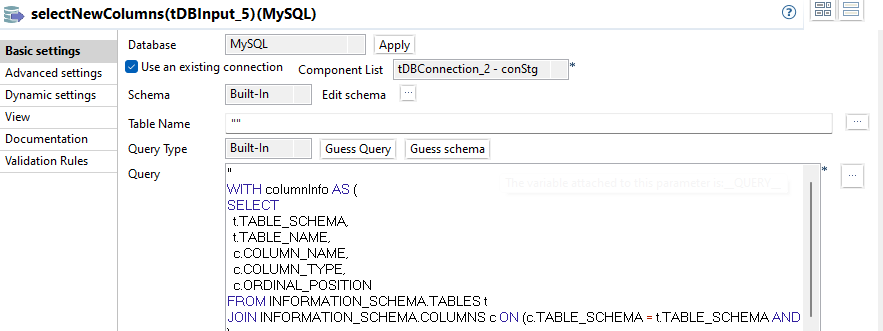
"
WITH columnInfo AS (
SELECT
t.TABLE_SCHEMA,
t.TABLE_NAME,
c.COLUMN_NAME,
c.COLUMN_TYPE,
c.ORDINAL_POSITION
FROM INFORMATION_SCHEMA.TABLES t
JOIN INFORMATION_SCHEMA.COLUMNS c ON (c.TABLE_SCHEMA = t.TABLE_SCHEMA AND c.TABLE_NAME = t.TABLE_NAME)
)
SELECT
c1.TABLE_NAME,
c1.COLUMN_NAME,
c1.COLUMN_TYPE
FROM columnInfo c1
LEFT JOIN columnInfo c2 ON (c2.TABLE_NAME = c1.TABLE_NAME AND c2.COLUMN_NAME = c1.COLUMN_NAME AND c2.TABLE_SCHEMA = '"+context.schemaNameRaw+"')
WHERE 1=1
AND c1.TABLE_SCHEMA = '"+context.schemaNameStg+"'
AND c2.TABLE_NAME IS NOT NULL
AND c2.COLUMN_NAME IS NULL
ORDER BY c1.TABLE_NAME ASC, c1.ORDINAL_POSITION ASC
"alterTableAddColumn
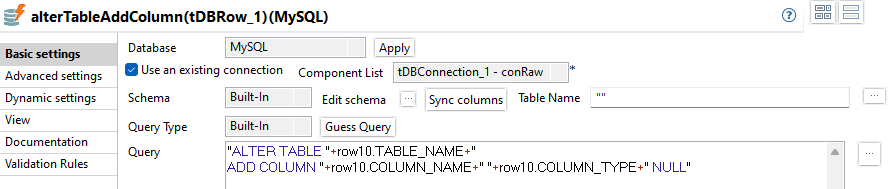
"ALTER TABLE "+row10.TABLE_NAME+"
ADD COLUMN "+row10.COLUMN_NAME+" "+row10.COLUMN_TYPE+" NULL"Delta-Bestimmung und Update
Dieser Subjob ist der umfangreichste. Betrachtet werden hier Daten, die geupdatet werden müssen. Anders formuliert: Es werden nur Tabellen betrachet, die im Staging und im Raw Schema vorhanden sind. Diese Unterscheidung ist in der unterschiedlichen Verarbeitung der Daten begründet: Tabellen, die noch nicht im Raw Schema existieren, können einfach neu angelegt werden und alle Daten aus dem Staging Schema übernommen werden. Es findet also gar keine Delta-Bestimmung im eigentlichen Sinne statt. Der Prozess mit neuen Tabellen wird im nächsten Subjob behandelt.
Für die Delta-Bestimmung in diesem Subjob müssen die Tabelleninhalte aus Staging und Raw Schema miteinander verglichen werden. Dies geschieht auch generisch, das heißt Tabellen-, Column-Namen und auch Primärschlüssel für die Join-Bedingung sind nicht vorprogrammiert, sondern müssen aus dem Information Schema selektiert werden. Die gesamten Metainformationen werden im ersten Schritt für alle Tabellen selektiert, bevor die Iterationen beginnen für geänderte, neue und gelöschte Daten, in denen sie Verwendung finden.
Außerdem werden den Auditinformationen in diesem Schritt angereichert. Das heißt die Zeitstempel für „Erstellt“, „letzte Änderung“ und „Gelöscht“ werden gesetzt.
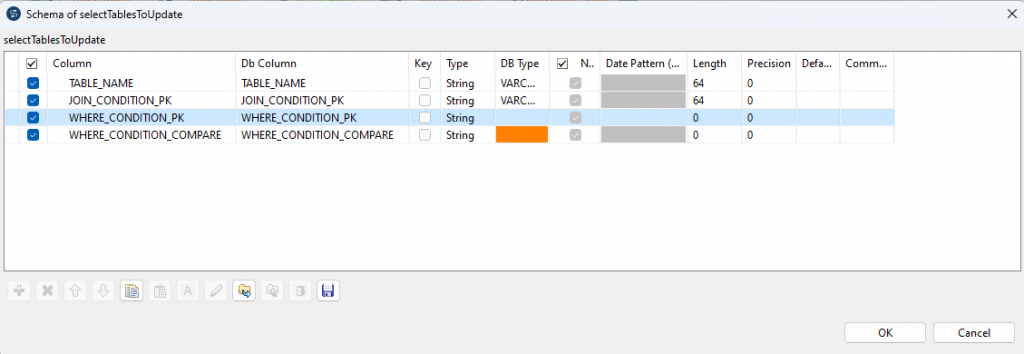
selectTablesToUpdate
In dieser Komponente werden die Metadaten für die generische Delta-Bestimmung selektiert. Dabei werden alle Tabellen aus dem Staging Schema betrachtet, die ebenfalls im Raw Schema existieren.
TABLE_NAME: Name der TabelleJOIN_CONDITION_PK: Generierte Join Bedingung für die 2 Tabellen aus Staging und Raw Schema. Wird in allen Queries verwendet.WHERE_CONDITION_PK: Generierte Where-Bedingung, die speziell für die Bestimmung der gelöschten Datensätze verwendet wird.WHERE_CONDITION_COMPARE: Generierte Where-Bedingungen, die speziell für die Bestimmung der geänderten Datensätze verwendet wird.
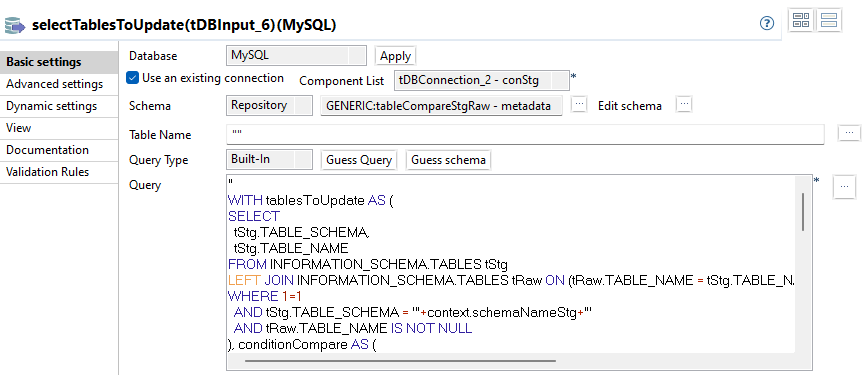
Das Schema wird in diesem Fall aus dem Repository verwendet und sieht wie folgt aus.
Das vollständige SQL:
"
WITH tablesToUpdate AS (
SELECT
tStg.TABLE_SCHEMA,
tStg.TABLE_NAME
FROM INFORMATION_SCHEMA.TABLES tStg
LEFT JOIN INFORMATION_SCHEMA.TABLES tRaw ON (tRaw.TABLE_NAME = tStg.TABLE_NAME AND traw.TABLE_SCHEMA = '"+context.schemaNameRaw+"')
WHERE 1=1
AND tStg.TABLE_SCHEMA = '"+context.schemaNameStg+"'
AND tRaw.TABLE_NAME IS NOT NULL
), conditionCompare AS (
SELECT
c.TABLE_SCHEMA,
c.TABLE_NAME,
GROUP_CONCAT(CONCAT('stg.',c.COLUMN_NAME, '<>','raw.',c.COLUMN_NAME) ORDER BY c.ORDINAL_POSITION ASC SEPARATOR ' OR ') AS WHERE_CONDITION_COMPARE
FROM INFORMATION_SCHEMA.COLUMNS c
WHERE 1=1
AND c.TABLE_SCHEMA = '"+context.schemaNameStg+"'
AND c.COLUMN_NAME NOT LIKE 'DWH%'
GROUP BY c.TABLE_SCHEMA, c.TABLE_NAME
), conditionPk AS (
SELECT
kcu.TABLE_SCHEMA,
kcu.TABLE_NAME,
GROUP_CONCAT(CONCAT('stg.',kcu.COLUMN_NAME, '=','raw.',kcu.COLUMN_NAME) ORDER BY kcu.ORDINAL_POSITION ASC SEPARATOR ' AND ') AS JOIN_CONDITION_PK,
GROUP_CONCAT(CONCAT('stg.',kcu.COLUMN_NAME, ' IS NULL') ORDER BY kcu.ORDINAL_POSITION ASC SEPARATOR ' AND ') AS WHERE_CONDITION_PK
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE kcu
WHERE 1=1
AND kcu.CONSTRAINT_NAME = 'PRIMARY'
AND kcu.TABLE_SCHEMA = '"+context.schemaNameStg+"'
GROUP BY TABLE_SCHEMA, TABLE_NAME
)
SELECT
t.TABLE_NAME,
pk.JOIN_CONDITION_PK,
pk.WHERE_CONDITION_PK,
comp.WHERE_CONDITION_COMPARE
FROM tablesToUpdate t
JOIN conditionPk pk ON (pk.TABLE_SCHEMA = t.TABLE_SCHEMA AND pk.TABLE_NAME = t.TABLE_NAME)
JOIN conditionCompare comp ON (comp.TABLE_SCHEMA = t.TABLE_SCHEMA AND comp.TABLE_NAME = t.TABLE_NAME)
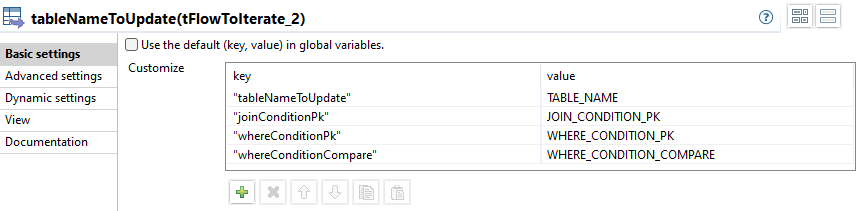
"tableNameToUpdate
Alle Flow Columns werden in globalen Variablen gespeichert.
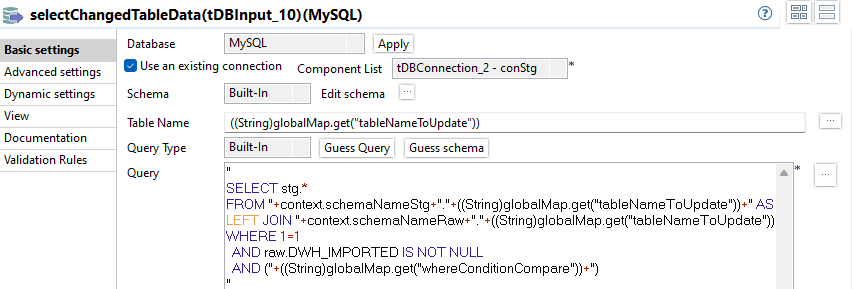
selectChangedTableData
Es werden nur diejenigen Datensätze selektiert, die bereits im Raw Schema existieren. Dies wird durch die Verwendung eines JOINs erreicht. Dabei kommt die zuvor gesetzte globale Variable joinConditionPk zum Einsatz.
In der WHERE Bedingung wird die Variable whereConditionCompare verwendet, die alle Columns einer Tabelle des Staging Schemas mit allen Columns der korrespondierenden Tabelle im Raw Schema vergleicht und dabei diejenigen Datensätze filtert, die mindestens eine Änderung aufweisen.
Die eingesetzte Where Bedingung entspricht folgendem Schema:
“stg.Column1 <> raw.Column1 OR stg.Column2 <> raw.Column2 OR …”
Das vollständige SQL:
"
SELECT stg.*
FROM "+context.schemaNameStg+"."+((String)globalMap.get("tableNameToUpdate"))+" AS stg
JOIN "+context.schemaNameRaw+"."+((String)globalMap.get("tableNameToUpdate"))+" AS raw ON ("+((String)globalMap.get("joinConditionPk"))+")
WHERE 1=1
AND ("+((String)globalMap.get("whereConditionCompare"))+")
"toRawSchema
Für geänderte Datensätze wird ein neuer Timestamp für DWH_UPDATED gesetzt.
Bereits vorhande Datensätze haben zwar auch schon ein DWH_IMPORTED Wert, der Einfachheit halber wird dieser aber nicht vorher mitselektiert, um ihn hier der entsprechenden Spalte zuzuweisen. Stattdessen wird der Wert ausgelassen und später so konfiguriert, dass er beim Update nicht berücksichtigt wird, sodass der Wert auf der DB erhalten bleibt und nicht durch einen NULL Wert ersetzt wird. Dazu mehr im nächsten Schritt.
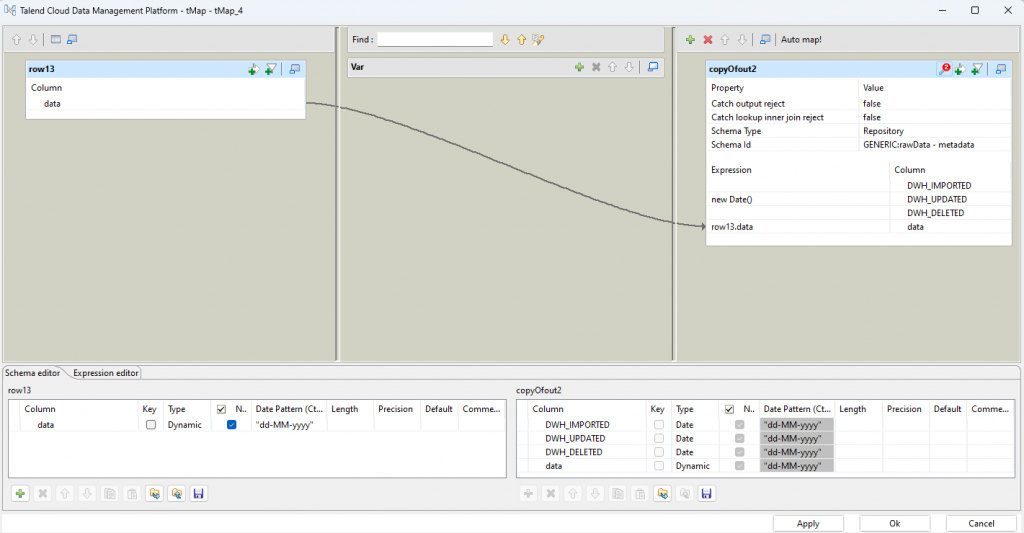
update (changed data)
Eine Besonderheit an dieser Stelle ist, dass Action on data als Insert or update on duplicate key or unique index konfiguriert ist. Dies ist nicht intuitiv, da ausschließlich Updates vorgenommen werden. Der Hintergrund ist eine Eigenheit von Talend.
Würde die Action auf Update eingestellt werden, käme zur Laufzeit eine Fehlermeldung, dass kein Update Key vorgegeben ist. Dieser kann aber nicht vorgegeben werden, weil ein dynamisches Schema verwendet wird, in dem sich der Primary Key verbirgt.
Mit der Einstellung Insert or Update on duplicate key verursacht der Primary Key in der Tabelle eine Constraint Violation beim Insert für den bereits vorhandenen Datensatz und der Insert wird für diesen Datensatz in ein Update umgewandelt.
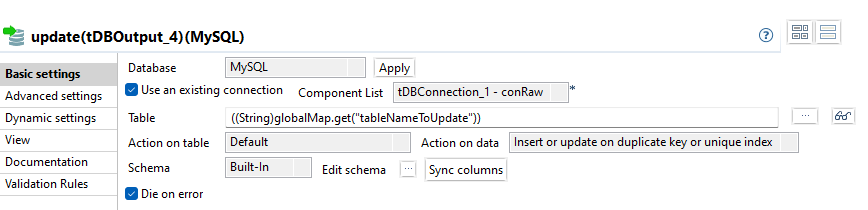
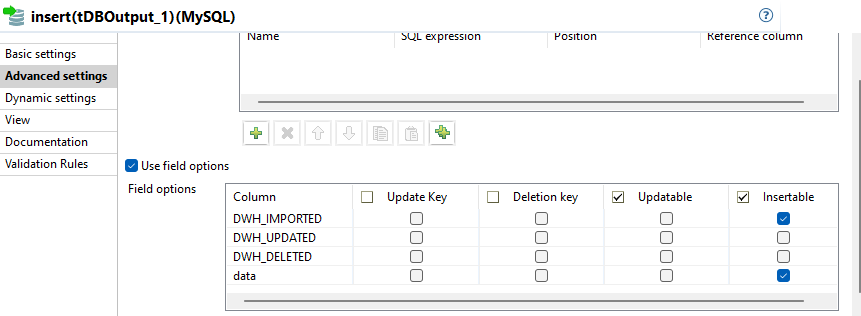
Es werden nur die Spalten DWH_UPDATED und data als Updatable markiert, denn nur diese dürfen in diesem Schritt geändert werden.
Wie im vorherigen Schritt erwähnt, wurde die Column DWH_IMPORTED für eine Wertzuweisung ausgelassen und ist daher NULL. Wäre die Column in den field options ebenfalls markiert, würde der Wert im Raw Schema mit NULL überschrieben werden.
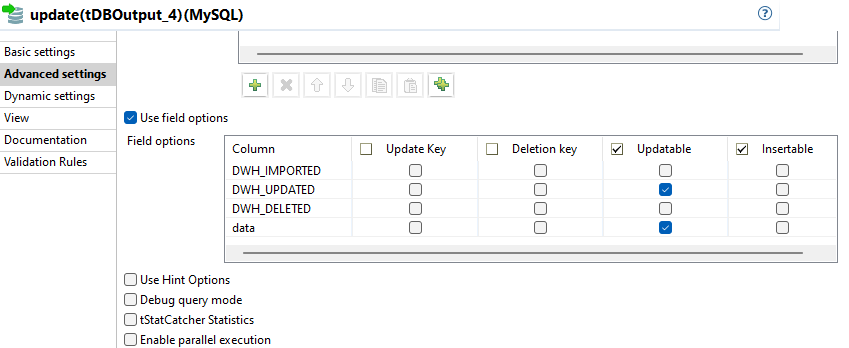
selectNewTableData
Es werden alle Datensätze selektiert, die noch nicht im Raw Schema existieren. Dies wird mit einem LEFT JOIN umgesetzt, die neuen Datensätze werden dann mit der WHERE Bedingung raw.DWH_IMPORTED IS NULL gefiltert.
Wie zuvor bei den geänderten Daten kommen auch wieder die gespeicherten globalen Variablen zum Einsatz.
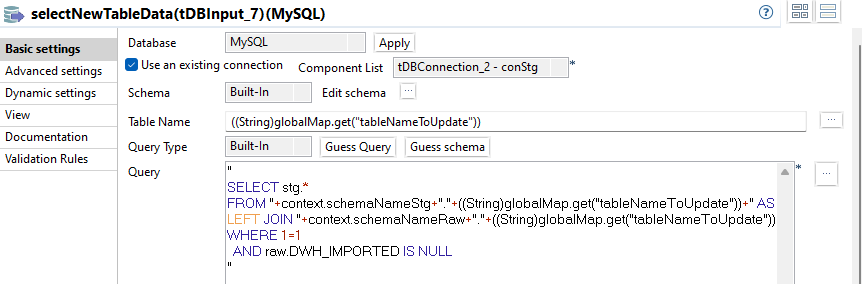
Das vollständige SQL:
"
SELECT stg.*
FROM "+context.schemaNameStg+"."+((String)globalMap.get("tableNameToUpdate"))+" AS stg
LEFT JOIN "+context.schemaNameRaw+"."+((String)globalMap.get("tableNameToUpdate"))+" AS raw ON ("+((String)globalMap.get("joinConditionPk"))+")
WHERE 1=1
AND raw.DWH_IMPORTED IS NULL
"toRawSchema
Neue Datensätze können nur einen Wert für DWH_IMPORTED erhalten.
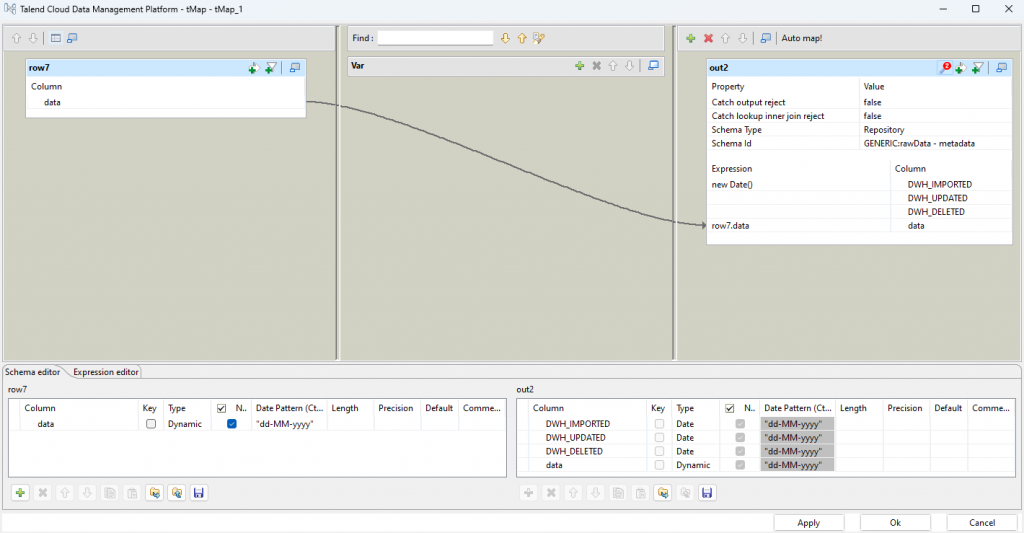
insert
Die Konfiguration des DBOutput für neue Records ist intuitiv:
- Action on table: Default
- Action on data: Insert
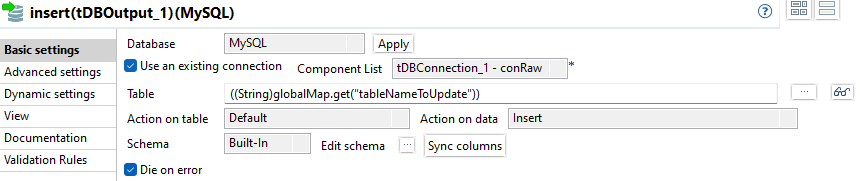
Die Columns DWH_IMPORTED und data werden als Insertable markiert.
selectDeletedTableData
Es werden alle gelöschten Datensätze ermittelt. Das Kriterium ist, dass sie nur im Raw Schema existieren, dies wird mittels LEFT JOIN umgesetzt. Zusätzlich wird noch die WHERE Bedingung raw.DWH_DELETED IS NULL angewendet, Datensätze mit gesetztem Timestamp wurden bereits zuvor als gelöscht markiert.
Eine weitere WHERE Bedingung wird mit einer weiteren globalen Variable whereConditionPk umgesetzt. Es handelt sich um die Abfrage, dass die PK Columns der gejointen stg Tabelle NULL sind. Sind sie NULL, wurde kein Datensatz im stg Schema gefunden und zeigt einen gelöschten Datensatz im QDM an.
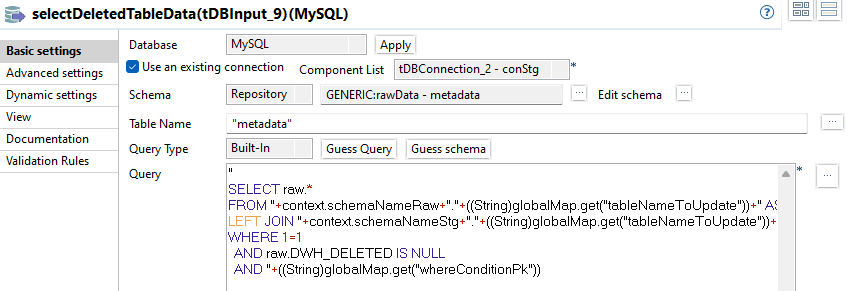
Das vollständige SQL:
"
SELECT raw.*
FROM "+context.schemaNameRaw+"."+((String)globalMap.get("tableNameToUpdate"))+" AS raw
LEFT JOIN "+context.schemaNameStg+"."+((String)globalMap.get("tableNameToUpdate"))+" AS stg ON ("+((String)globalMap.get("joinConditionPk"))+")
WHERE 1=1
AND raw.DWH_DELETED IS NULL
AND "+((String)globalMap.get("whereConditionPk"))setDeletedDate
Für gelöschte Datensätze kann nur ein entsprechender Timestmap für DWH_DELETED gesetzt werden. Daher erfolgt auch kein Mapping der übrigen Felder.
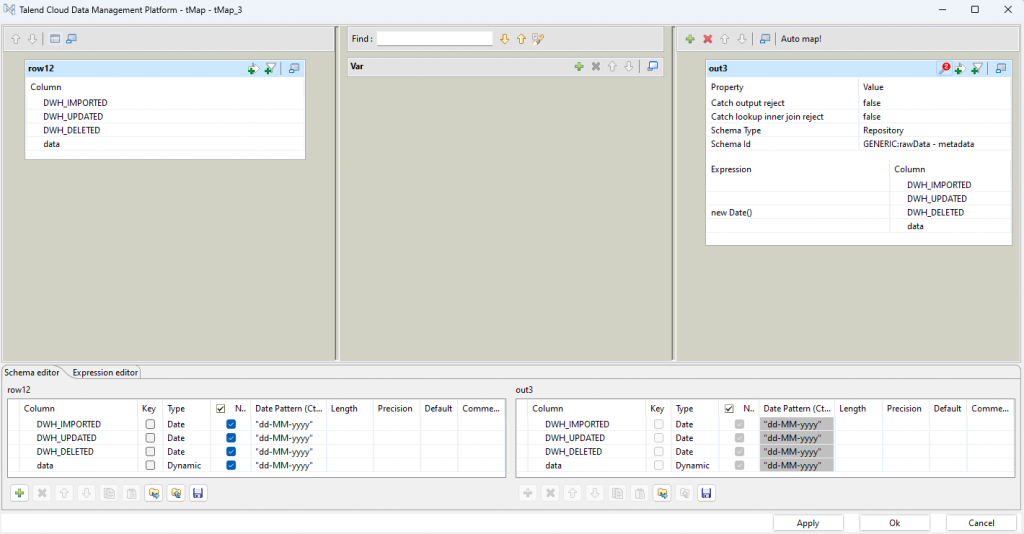
update (deleted data)
Wie schon bei den geänderten Daten, werden die Actions gewählt:
- Action on table: Default
- Action on data: Insert or update on duplicate key or unique index
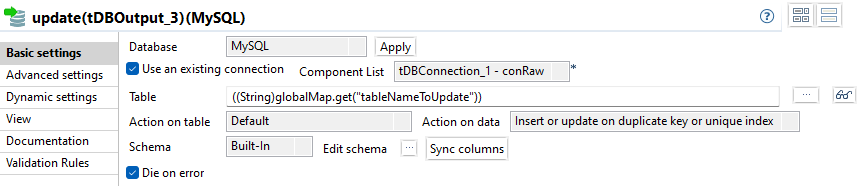
Die Column DWH_DELETED wird als einzige als Updatable markiert.
Neue Tabellen erstellen und Daten importieren
Im letzten Subjob werden Tabellen erstellt, die im QDM hinzugekommen sind und noch nicht im Raw Schema existieren. Ebenso werden die enthaltenen Daten komplett übernommen und abschließend die Primary Keys erstellt. Die dafür notwendigen Informationen wird aus dem INFORMATION_SCHEMA für die Tabellen des Staging Schemas entnommen.
Bei der allerersten Ausführung des ELT Prozesses ist dies der einzige ausgeführte Subjob, weil es nur neue Tabellen gibt, die noch nicht im Raw Schema existieren.
Im Folgenden wird auf erklärenden Text verzichtet, da es sich inhaltlich um eine Wiederholung und Kombination des Vorgehens vom Laden des Staging Schemas und der Delta-Bestimmung handelt.
selectTablesToCreate
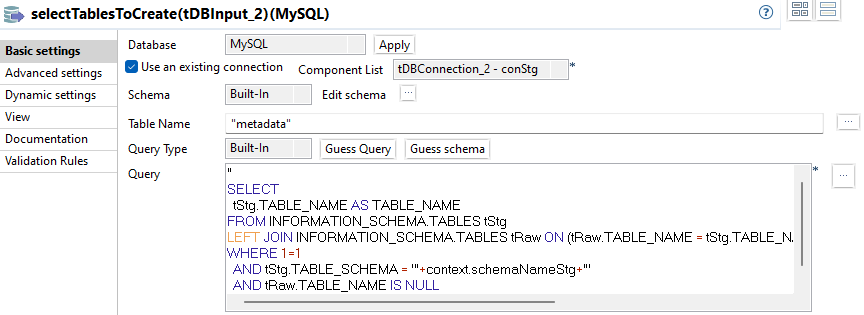
Das vollständige SQL:
"
SELECT
tStg.TABLE_NAME AS TABLE_NAME
FROM INFORMATION_SCHEMA.TABLES tStg
LEFT JOIN INFORMATION_SCHEMA.TABLES tRaw ON (tRaw.TABLE_NAME = tStg.TABLE_NAME AND traw.TABLE_SCHEMA = '"+context.schemaNameRaw+"')
WHERE 1=1
AND tStg.TABLE_SCHEMA = '"+context.schemaNameStg+"'
AND tRaw.TABLE_NAME IS NULL
"tableNameToCreate
selectTableData
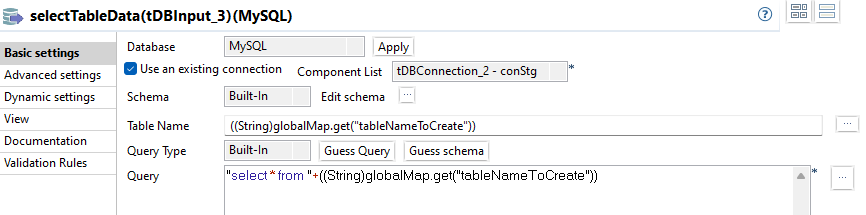
Das vollständige SQL:
"select * from "+((String)globalMap.get("tableNameToCreate"))toRawSchema
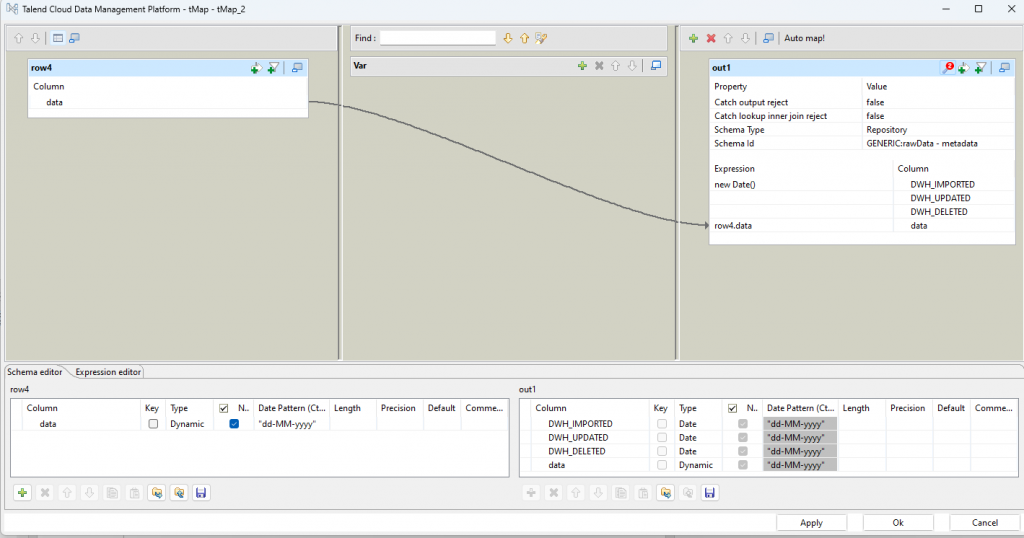
createTableAndInsert
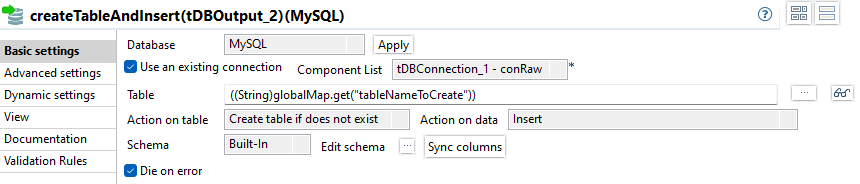
Das vollständige SQL:
"
SELECT
kcu.TABLE_NAME,
GROUP_CONCAT(kcu.COLUMN_NAME ORDER BY kcu.ORDINAL_POSITION ASC SEPARATOR ', ') AS COLUMN_NAMES
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE kcu
WHERE 1=1
AND kcu.CONSTRAINT_NAME = 'PRIMARY'
AND kcu.TABLE_SCHEMA = 'DATA_MIGRATION_STG'
AND kcu.TABLE_NAME = '"+((String)globalMap.get("tableNameToCreate"))+"'
GROUP BY TABLE_SCHEMA, TABLE_NAME
"addPrimaryKey
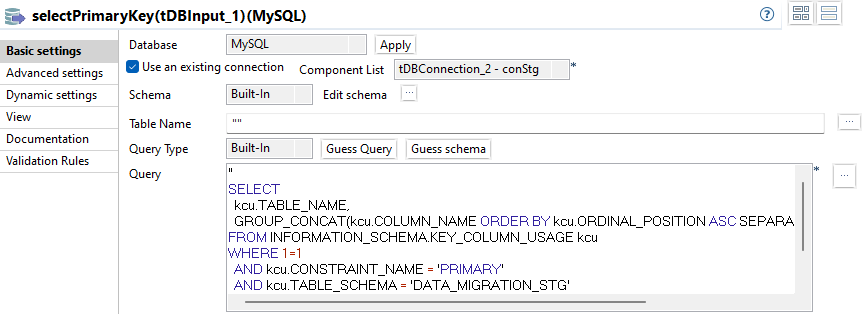
Das vollständige SQL:
"ALTER TABLE "+row1.TABLE_NAME+" ADD CONSTRAINT PRIMARY KEY ("+row1.COLUMN_NAMES+")" Zusammenfassung
Die vorgestellte Vorgehensweise eignet sich für eine schnelle Integration eines beliebigen Schemas und kann auf verschiedene Datenbanken angewendet, solange Zugriff auf die Schemainformationen besteht.
Der Prozess ist auch tollerant gegenüber Erweiterungen des QDM, sodass auch neue Tabellen und Spalten umgehend integriert werden ohne dass ein manueller Eingriff erfolgen muss.
Es folgen noch ein paar Erweiterungsmöglichkeiten, die den Prozess noch robuster machen:
Monitoring von Datenmodelländerungen
Der vorgestellte Prozess geht sehr flexibel mit wegfallenden und neu hinzukommenden Columns um, was zu einem Großteil der Anwendungsfälle auch als Behandlung ausreicht.
Allerdings können auch Refactorings im QDM auftreten, bei denen eine Spalte umbenannt wird. Dies resultiert im IDM logisch gesehen in einer wegfallenden Spalte und in einer neu hinzukommenden Spalte mit einem anderen Namen, aber gleichem Datentyp. Entscheidend in diesem Zusammenhang ist aber, dass die Semantik ebenfalls dieselbe ist.
Datawarehouse Prozesse, die sich auf die im QDM weggefallene Column beziehen, bekommen keine neuen Werte, weil die Column im IDM erhalten bleibt und neue Records mit NULL belegt werden. Dadurch laufen sie weiter und produzieren möglicherweise falsche Daten im Datawarehouse, falls die NULL Werte gegen keine Business Regel verstoßen.
Ähnlich sieht es aus, wenn ein Refactoring im QDM zum Aufteilen einer Spalte in mehrere neue Spalten führt, also eine Datentransformation notwendig macht.
Unter diesem Gesichtspunkt sollte genau auf diese Art Datenmodelländerung reagiert werden: Mindestens eine Column in einer Tabelle fällt weg, mindestens eine Column in der gleichen Tabelle kommt hinzu. Ungeachtet des Datentyps.
Datentypänderungen berücksichtigen
Eine Datentypänderung einer Column ist im vorgestellten Prozess als Ausnahme definiert, die zum Abbruch führt. Streng genommen können Datentypänderungen behandelt werden, die die Präzison erhöhen. Konkret kann eine Column, die als VARCHAR(25) definiert war bespielsweise auf VARCHAR(100) vergrößert werden.
Änderungen im Primary Key berücksichtigen
Der Primary Key wird im Raw Schema einmalig für eine neue Tabelle erstellt. Im Staging Schema wird er bei jedem Durchlauf erneut angelegt und bei der Delta-Bestimmung werden die Metainformationen aus dem Staging Schema verwendet, um die Primary Key Columns für einen Join zwischen Staging und Raw Tabellen zu bestimmen.
Handelt es sich beim QDM um ein Datenmodell, das ausschließlich mit Surrogatschlüsseln arbeitet, so ist eine Änderung eines Primary Keys sehr unwahrscheinlich.
Handelt es sich beim QDM um eine Individualsoftware oder um ein Produkt, in dem viel individuelles Customizing durchgeführt wird und dabei natürliche Schlüssel verwendet, ist die Wahrscheinlichkeit für eine Primärschlüsseländerung schon größer.
In jedem Fall sollte die Gleichheit des PK geprüft werden und eine Abweichung zum Abbruch führen. Die Auswirkungen und notwendigen Maßnahmen einer solchen Änderungen müssen situativ ermittelt werden.
Löschen des Staging Schemas
Durch das vorgestellte Vorgehen wird basierend auf jeder Tabelle des QDM die korrespondierende Tabelle im Staging Schema neu angelegt. Allerdings bleiben Tabellen im Staging Schema erhalten, wenn die korrespondierenden Tabellen im QDM wegfallen. Dies kann abhängig von der Größe des Inhalts wenig Auswirkung auf Speicherbedarf und Laufzeitverhalten des Prozesses haben, kann aber Auswertungen verfälschen, die sich auf die verarbeiteten Tabellen und Datensätzen beziehen und darüber hinaus entstehen Datenleichen.
Ein weiterer Subjob kann Abhilfe schaffen, der zu Beginn für jede im Staging Schema enthaltene Tabelle ein drop Table Statement ausführt.
Speichern der Run Informationen
Für Auswertungen und ein Prozessmonitoring ist es hilfreich, die Run Informationen der Datenmigration zu speichern. Informationen wie Startzeitpunkt, Endzeitpunkt, Status können ausgewertet werden und Aufschluss darüber geben, wie sich die gesamte Integration über die Zeit verhält. Gerade bei einem Prozess ohne Delta-Extract kann dann rückblickend abgeschätzt werden wie sich das Laufzeitverhalten in der Zukunft darstellen wird und ob weitere Maßnahmen erfolgen müssen.