Dieser Artikel zielt auf den Anwendungsfall: Ich brauche für Tests irgendein Datenmodell (DM) für meine Datenbank X, ich möchte es nicht selber erfinden bzw. definieren und ich möchte keine lizenzpflichtigen Produkte verwenden.
Ausgangspunkt für diese Methode ist ein frei verfügbares DM im Internet, das dem Anspruch “irgendeins” genügt und für das SQL Dateien vorliegen. Kann ein geeignetes DM gefunden werden und die SQLs liegen sogar schon im Format passend zur DBX vor: Arbeit gespart, es kann direkt losgehen. Dieser Artikel braucht ab hier nicht weitergelesen werden.
Wenn ein geeignetes DM für eine abweichende DB gefunden werden kann oder ein bereits vorhandenes DM favorisiert wird, das aber für eine andere DB vorliegt, gibt es Möglichkeiten dieses DM transformieren zu lassen.
Die hier vorgestellte Methode verwendet Liquibase in der Open Source Variante.
Liquibase kurz erklärt
Der orginäre Einsatzzweck von Liquibase ist das Management von Datenmodellrevisionen für eine Software, dessen DM sich im Laufe der Zeit verändert. Diese Änderung des DM wird mit Liquibase verwaltet.
Die Änderungen werden in sogenannten Change Sets festgehalten. Ein Change Set ist eine Änderung am DM und kann dabei ein oder mehrere SQL Anweisungen enthalten. Change Sets werden in Change Log Dateien zusammengefasst.
Liquibase bietet Kommandos, mit deren Hilfe Change Logs erstellt werden können, sodass die Änderungen nicht mehr per Hand geschrieben werden müssen. Neben dem Feature 2 Datenbanken miteinander zu vergleichen und die Differenz in einem Change Log zu speichern, bietet Liquibase auch ein Feature den gesamten Inhalt einer DB in einem Change Log zusammenzufassen. Dabei kann die verwendete DB von Oracle sein und das generierte Change Log SQL für PostgreSQL enthalten. Dieses Feature wird in diesem Artikel verwendet.
Liquibase konfigurieren
Die Konfiguration von Liquibase erfolgt über ein properties file. Im Default lautet der Name liquibase.properties.
Der Inhalt der Konfigurationsdatei lautet wie folgt:
overwriteOutputFile=true
driver=oracle.jdbc.driver.OracleDriver
url=jdbc:oracle:thin:@localhost:1521/XEPDB1
username=OT
password=yourPassword
changeLogFile=changeLog.postgresql.sql- overwriteOutputFile=true: Mehrfaches Ausführen der Kommandos zum Generieren überschreibt das vorherige Change Log File. Ist das Property nicht gesetzt, bricht Liquibase die wiederholte Generierung ab mit dem Hinweis, dass bereits ein Change Log File existiert.
- driver: Java Klassenname des zu verwendeten Treibers. In diesem Fall für Oracle.
- url: Die JDBC Connection URL
- username: Benutzname für die DB Connection
- password: Passwort für die DB Connection
- changeLogFile: Name des erzeugten Change Log File relativ zum Working Directory. Der Teil “postgresql” ist funktional: Die Angabe steuert, in welchem DB-spezifischen Format das SQL ausgebenen wird. Ebenso ist die Dateiendung “sql” obligatorisch.
Unterstützte Datenbanken
Liquibase unterstützt für die vorgestellte SQL Generierung 17 Datenbanken laut offizieller Dokumentation auf docs.liquibase.com:
DB2/LUW, DB2/z, Derby, Firebird, H2, HyperSQL, INGRES, Informix, MariaDB, MySQL, Oracle, PostgreSQL, Snowflake, SQL Server, SQLite, Sybase, Sybase Anywhere
DB Type Namen herausfinden
Leider listet die Dokumentation nicht die tatsächlich zu verwendeten DB Type Namen für das generate-changelog Kommando. Für den Fall, dass einem der Name unbekannt ist, kann das Kommando einfach mit einer absichtlich falschen Konfiguration für das changeLogFile ausgeführt werden, liquibase erkennt dies und listet dann in der Kommandozeile alle bekannten DB Type Namen auf (bspw.: changeLogFile=changeLog.UNBEKANNT.sql):
cockroachdb, snowflake, edb, firebird, oracle, sybase, sqlite, hsqldb, db2z, h2, informix, mariadb, unsupported, postgresql, db2, ingres, asany, derby, mysql, mssql
Zusätzliche JDBC Treiber
Für Oracle, PostgreSQL wie auch einige andere Datenbanken liegen bereits JDBC Treiber im Verzeichnis internal/lib von Liquibase vor. Bei der Verwendung einer anderen DB kann es notwendig sein, einen weiteren Treiber zur Verfügung zu stellen.
Datenmodell generieren
Die Konfiguration wurde in einem separaten Verzeichnis erstellt, das als Workspace dient.
Auf der Kommandozeile wird in dieses Verzeichnis gewechselt und folgendes Liquibase Kommando ausgeführt:
liquibase generate-changelog --diff-types tables,columns,indexes,foreignkeys,primarykeys,data,sequences,uniqueconstraints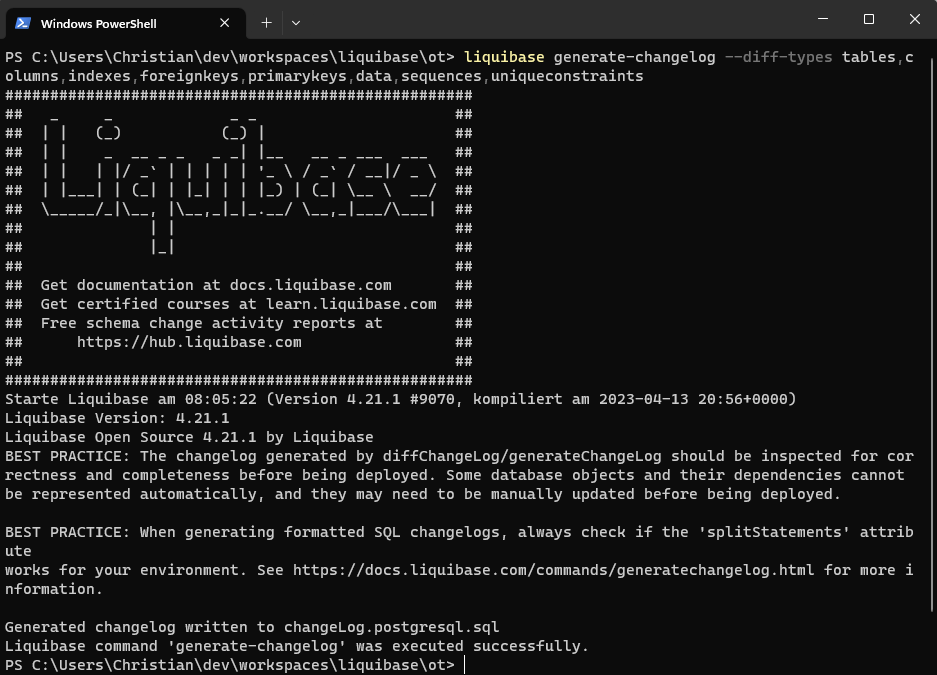
Das Kommando generate-changelog betrachtet den Zustand der gesamten DB und erzeugt ein Change Log File, das den gesamten Zustand reproduziert.
Der Parameter diff-types gibt vor, welche DB Objekte betrachtet und in das Change Log File exportiert werden sollen. Wird der Parameter weggelassen, gilt der Default und die in der DB enthaltenen Daten werden nicht betrachtet. Es werden also keine INSERT Statements generiert. Soll von diesem Default abgewichen werden, müssen alle DB Objekte gelistet werden, die enthalten sein sollen.
Das Ergebnis des Kommandos befindet sich dann in der Datei changeLog.postgresql.sql wie in liquibase.properties angegeben.
Datenmodell anpassen
Wie der Hinweis zum Best Practice in der Kommandozeilenmeldung schon andeutet, kann es erforderlich sein, das generierte SQL Skript zu korrigieren. Dies beruht auf DB-Objekten, -Typen oder -Regeln, die inkompatibel zum Zielsystem sind.
Im Oracle DM wurde beispielsweise der Datentyp NUMBER für alle Primary Keys verwendet:
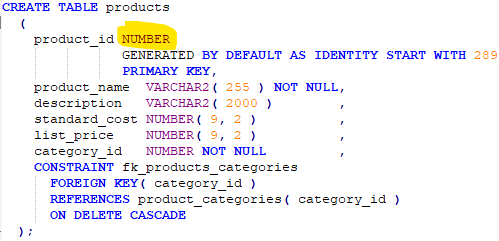
Außerdem werden Fremdschlüsselfelder, die auf die NUMBER PKs verweisen, weiter eingeschränkt wie z.B. mit NUMBER(12,0).
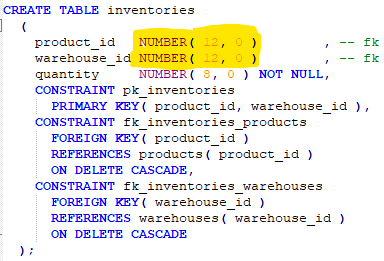
PostgreSQL kennt einen Datentyp mit der Bezeichnung NUMERIC, der dem Oracle Datentyp NUMBER entspricht. Erwartungsgemäß enthält das generierte SQL bei den PKs NUMERIC und bei den Fremdschlüsselfeldern noch eine Längendefinition wie NUMERIC(12,0) oder NUMERIC(6, 0).
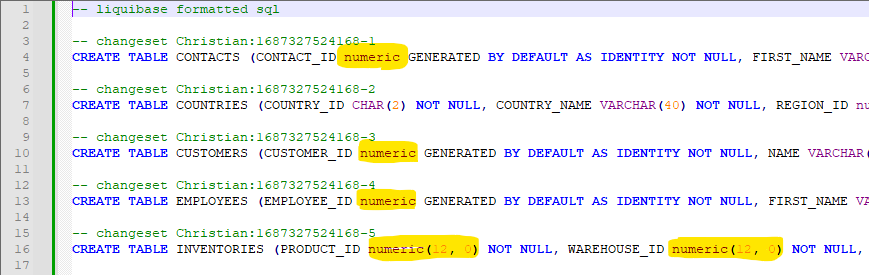
Wird das generierte Skript auf der PostgreSQL ausgeführt, bricht es mit einer Fehlermeldung ab:

Primary Key Columns dürfen in PostgreSQL also nur als ganzzahlige Datentypen SMALLINT, INTEGER oder BIGINT definiert werden.
An dieser Stelle wird deutlich wo die Grenzen von Liquibase und anderen Tools liegen, die nicht die Semantik des DM vollständig interpretieren können und somit kein folgerichtiges Modell für eine andere DB genieren können. Daher können kleine manuelle Eingegriffe notwendig sein, um das generierte SQL Skript zu korrigieren.
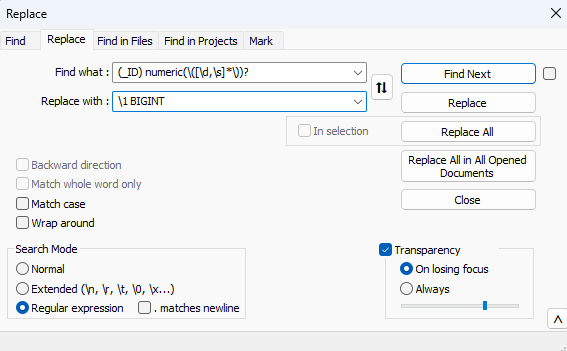
Die Analyse ergibt, dass alle betroffenen PK und FK Columns auf “_ID” enden. Der Feldbezeichnung folgt die Datentypbezeichnung “numeric” und bei den FK Columns (und auch bei manchen PK Columns) folgen anschließend noch verschiedene Längendefinitionen wie z.B. “(12, 0)”. Dieses Muster lässt sich mit einem RegEx finden und durch den gewünschten Datentyp ersetzen. Der Einfachheit halber wird als Korrektur für alle Surrogatschlüssel der größtmögliche Datentyp BIGINT gewählt.
RegEx zum Finden:
(_ID) numeric(\([\d,\s]*\))?Ausdruck zum Ersetzen:
\1 BIGINTDiese Operation kann bspw. mit Notepad++ durchgeführt werden, welches als Freeware kostenlos erhältlich ist und RegEx Ersetzungen ermöglicht.
Sobald die NUMERIC Datentypen korrigiert worden sind, lässt sich das SQL Skript fehlerfrei ausführen und das DM in eine PostgreSQL DB übernehmen.
Zusammenfassung
Liquibase unterstützt bei der Transformation eines Datenmodells einer spezifischen relationalen DB hin zu einem DM für eine andere relationale DB. Dabei liest es die Metainformationen einer bestehenden DB aus und generiert ein SQL Skript für ein spezifisches DBMS. Optional können auch INSERT Statements generiert werden um den Datenbestand zu übernehmen.
Mit diesem Tool kann eine breite Palette von insgesamt 17 verschiedenen DBMS abgedeckt werden, darunter die großen Namen wie Snowflake, Oracle, SQL Server, DB2, Maria DB, MySQL und PostgreSQL.
Es gibt spezifische Regeln für spezifische Datenbanken, die Liquibase bei der Transformation eines DM von einer DB zu einer anderen nicht selbstständig umsetzen kann und manuelle Korrekturen erfordern. Geübte Anwender können diese Korrekturen mittels Reg Ex effizient halbautomatisch durchführen.
Die vorgestellte Methode ermöglicht es mit vertretbarem Aufwand für einen einmaligen Anwendungsfall ein Datenmodell für ein spezifisches RDBMS zu genieren.