Dieser Artikel beschreibt ein Design für Talend Jobs, das die Verwendung in einer tJob Komponente innerhalb eines Flows vereinfacht.
Die Motivation, einen Teil der Prozesslogik in einen separaten Job zu verlegen, kann verschiedene Gründe haben:
- Separation of Concerns / Wiederverwendbarkeit
- Übersichtlichkeit
- Maximale Größe einer Methode in Java
Maximale Größe einer Methode in Java
Der kompilierte Byte Code einer Methode in Java darf eine Maximallänge von 65535 Bytes nicht überschreiten.
Die Verarbeitungslogik eines Subjobs in Talend wird in einer einzigen Methode zusammengefasst. Mit einer ausreichend großen Menge an Verarbeitungsschritten innerhalb eines Subjobs kann der generierte Bytecode der dazugehörigen Methode zu groß werden und die Ausführung führt zu einem Fehler.
Als Lösung für dieses Problem kann neben der Aufteilung der Prozesslogik auf mehrere Jobs noch eine weitere Methode angewendet werden. Es besteht die Möglichkeit, den Flow eines zu langen Subjobs bspw. in einer FileOutput Komponente enden zu lassen und die Verarbeitung der Datei in einem weiteren Subjob wiederaufzunehmen. Dieses Vorgehen führt allerdings zum nächten Thema.
Übersichtlichkeit
Große Jobs in Talend sind schwieriger zu warten als kleinere. Die sinnvolle Benennung von Komponenten erfordert einen gewissen Mindestabstand zwischen den Komponenten, um die Lesbarkeit zu gewährleisten. Die Abfolge von notwendigen Initialierungen zu Beginn eines Jobs und Prüfungen von Voraussetzungen (Asserts im weitesten Sinne) kann schon einen großen Teil der Ansicht im Job Editor einnehmen. Die eigentliche ETL-Verarbeitung eines Jobs kann ebenfalls schnell mehrere Subjobs beinhalten, die unter Berücksichtigung des Abstandes zwischen den Komponenten dazu führen, dass der gesamte Job nur durch Herauszoomen zu sehen ist.
Wer schon einmal einen Job dieser Größe erstellt hat und dabei entweder scrollen oder zoomen musste, weiß wie hinderlich die fehlende Übersicht sein kann. Nicht selten bleiben derartige, unübersichtliche Jobs genau in dem Zustand wie sie initial produktiv gegangen sind. Dies kann bzw. wird zu einem erhöhten Wartungsaufwand führen, vor allem wenn der ursprüngliche Autor nicht mehr anwesend.
Separation of Concerns / Wiederverwendbarkeit
Ein häufiges Muster, das im Rahmen von Separation of Concernes bei ETL Prozessen zu beobachten ist, ist die Einteilung in Stages bzw. Stufen. Dabei liegen Konzepte zugrunde, die bestimmte Verarbeitungsschritte, Prüfungen und Transformationen eine bestimmten Stufe zuordnen. Die Aufteilung der Logik in verschiedene Jobs folgt dann dem zugrunde liegendem Konzept.
Die Aufteilung von Logik in Jobs zur Wiederverwendbarkeit ist ein Spezialfall von Separation of Concerns. Es handelt sich dabei um Abläufe, die mehrfach im Projekt verwendet werden können. Anstatt eine Logik immer wieder mittels Copy Paste in verschiedenen Jobs zu vervielfältigen, wird diese einmalig in einem Job implementiert, der dann wiederverwendet wird. Dies hat den weiteren Vorteil, dass im Falle einer Änderung diese nur in einem Job vorgenommen werden muss.
Die Parametrisierung eines Jobs wird mit Kontextvariablen vorgenommen, im Allgemeinen sind dies einfache Parameter, die z.B. Verzeichnispfade definieren, Umgebungsvariablen oder Schalter. Interessanter wird es wenn der Job in einem Flow eingebettet werden soll und ihm ein Row Objekt für die Weiterverarbeitung mit einem bestimmten Schema übergeben werden soll und der Job ebenso wieder ein Row Objekt zurückgeben soll.
Job Design
Für die Übergabe der Row Variablen in den Job und die Rückabe aus dem Job werden Context Variablen verwendet.
Um für die Übergabe und Rückgabe beliebige Row Schemata zu ermöglichen, wird Custom Code verwendet, der automatisch Werte kopiert.
Um die Ausführung des Jobs während der Entwicklung zu unterstützen, werden Default Werte für Übergabe und Rückgabewerte verwendet.
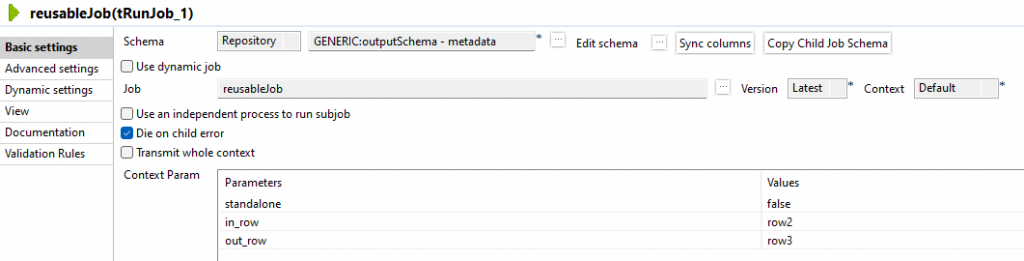
Die Wiederverwendung wird mittels tJob Komponente realisiert.
Schemata
Es wird empfohlen für die Übergabe- (Input) und Rückgabe-Werte (Output) vordefinierte Schemata zu verwenden. Im diesem Beispiel werden 2 verschiedene Schemata für Input und Output verwendet, genauso können sich auf Anwendungsfälle ergeben, in denen dasselbe Schema verwendet wird.
Input Schema
Eine Schema mit 2 Columns.
- column1: Ein String Wert
- column2: Ein int Wert
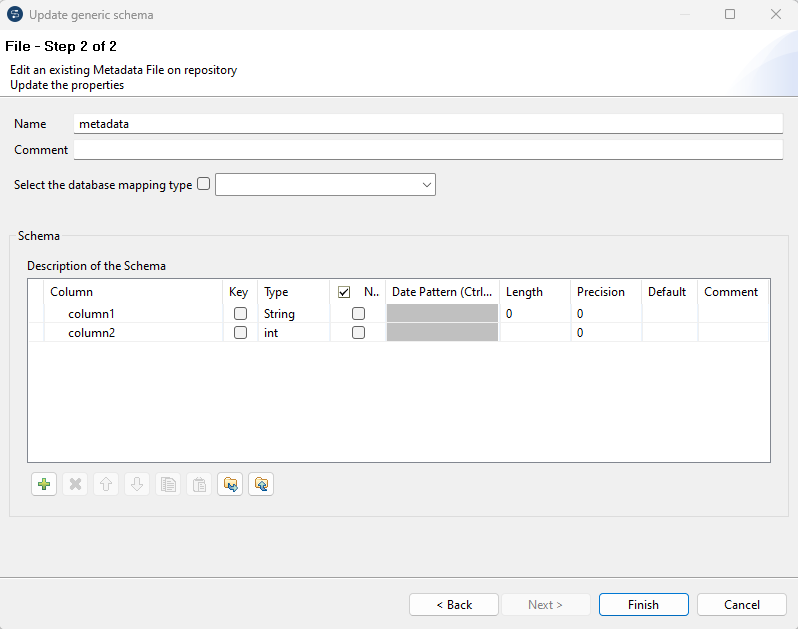
Output Schema
Ein Schema mit einer Column.
- concatenatedColumns: Ein String Wert, der im Beispiel aus den 2 Werten des Input Schemas gebildet wird
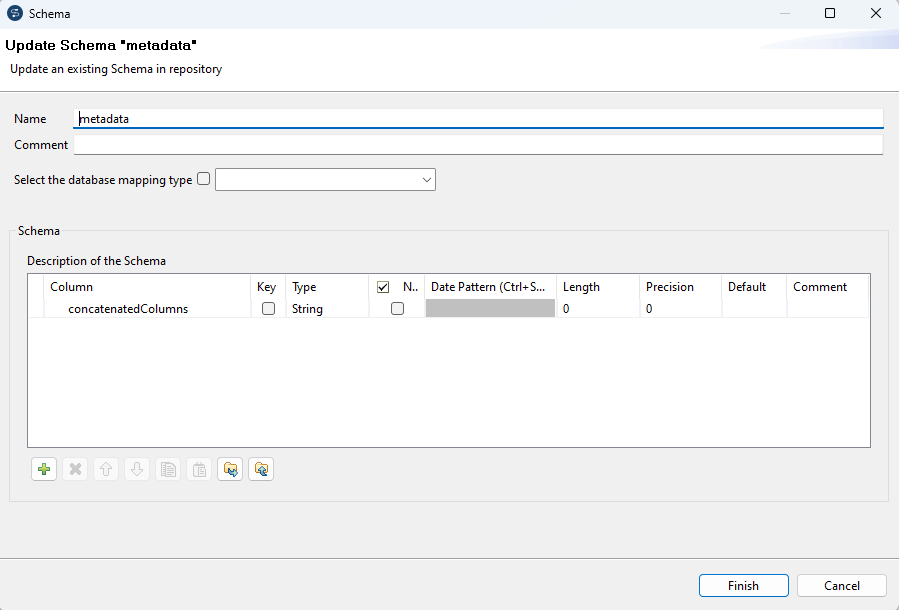
Job Context
Das Design sieht für einen wiederverwendbaren Job 3 Variablen vor:

- standalone: Gibt an, ob der Job eigentständig läuft. Abhängig von diesem Schalter werden Default Werte für In und Out Parameter gesetzt
- in_row: Das eingehende Row Object im aufrufendenen Flow, das im Job verarbeitet wird
- out_row: Das ausgehende Row Object im aufrufenden Flow, in welches dieser Job die Verarbeitungsergebnisse schreibt
ObjectMapper für Übergabe- und Rückgabewerte
Context Variablen können keine konkreten Row Schema Typen annehmen. Soll eine Row übergeben werden, muss also der Typ Object vergeben werden.
Da in Talend der Typ einer Row nicht dem Typ eines vordefinierten Schemas entspricht und der Row Typ auch nur exklusiv in dem Job vorhanden ist, in dem die Row definiert ist, kann das aus dem aufrufenden Job übergebene Objekt in_row im aufgerufenen Job nicht zu einem Row Typ mit selbem Schema gecastet werden.
Stattdessen werden die Werte einer Row mit Hilfe von Java Reflections von einem zum anderen Objekt kopiert. Der dazu benötigte Code kann in Talend unter Global Routines erstellt werden.
Der hier vorgestellte ObjectMapper bietet dafür eine statische Methode an, der 2 Parameter übergeben werden können:
from: Es handelt sich um das Objekt, von dem Werte kopiert werden sollento: Es handelt sich um das Objekt, in das Werte kopiert werden sollen
Das Kopieren erfolgt anhand der Feldnamen in den Objekten. Ist ein Feldname in from und to vorhanden, wird der Wert kopiert.
Es wird dabei nicht überprüft, ob die übergebenen Objekte from und to insgesamt gleiche Felder haben. Sie können sich unterscheiden. Es werden nur die Werte der Felder kopiert, die in beiden Objekten vorhanden sind.
Werden Objekte mit gleichem Feldnamen aber unterschiedlichem Typ übergeben, kommt es zu einer Runtime Exception.
Statische Felder werden beim Kopieren ignoriert. Diese werden von Talend in den entsprechenden Typen generiert, beziehen sich aber nicht auf die Nutzdaten und sind teilweise auch final.
package routines;
import java.lang.reflect.Field;
import java.lang.reflect.Modifier;
public class ObjectMapper {
public static void copyValues(Object from, Object to) throws IllegalAccessException {
Class<?> fromClass = from.getClass();
Class<?> toClass = to.getClass();
Field[] fromFields = fromClass.getDeclaredFields();
Field[] toFields = toClass.getDeclaredFields();
for (Field fromField : fromFields) {
if (!Modifier.isStatic(fromField.getModifiers())) {
fromField.setAccessible(true);
String fieldName = fromField.getName();
for (Field toField : toFields) {
toField.setAccessible(true);
if (toField.getName().equals(fieldName)) {
Object value = fromField.get(from);
toField.set(to, value);
break;
}
}
}
}
}
}Job
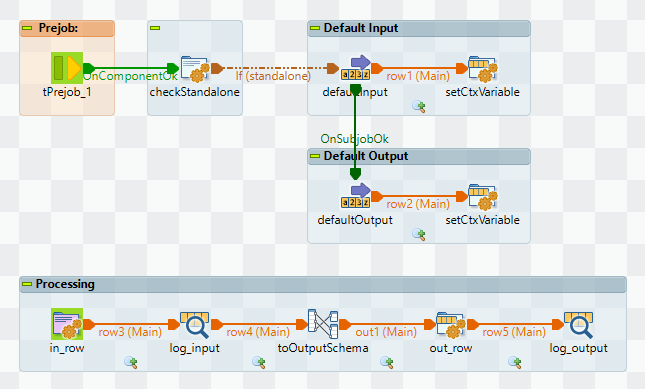
Innerhalb von Prejob werden die Default Werte für in_row und out_row gesetzt, um die Standalone Ausführung des Jobs zu ermöglichen. Dazu wird geprüft, ob context.standalone == true gilt. In diesem Fall wird erst in_row und anschließend out_row gesetzt.
In der Verarbeitung (Subjob Processing) wird als erstes context.in_row in row3 kopiert. Es folgt eine Transformation, dies ist examplarisch für die wiederverwendbare Funktion des Jobs. Das Ergebnis der Transformation out1 entspricht dem Output Schema und wird mittels ObjectMapper in context.out_row kopiert.
Defaults
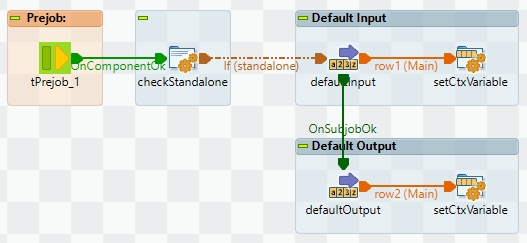
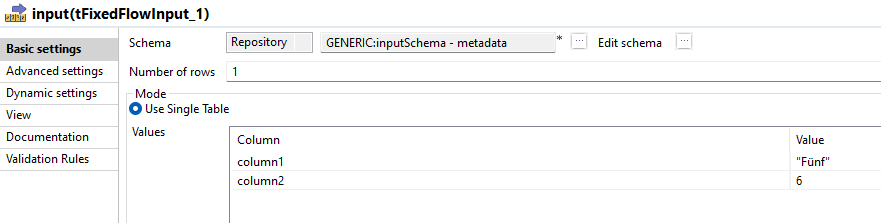
Die Default Werte für in_row und out_row werden gesetzt, damit der Job als Ganzes auch standalone ausgeführt werden kann (z.B. während der Entwicklung). Wären die Default Werte nicht gesetzt, würde die Ausführung auf Nullpointer Exceptions laufen.
Wie bereits erwähnt gibt es eine Context Variable standalone, die Bestandteil dieser Logik ist. Es handelt sich um eine Boolean Variable, deren Default Wert true ist. Das heißt, für die standalone Ausführung muss nichts umkonfiguriert werden, wird der Job in einem anderen wiederverwendet, muss diese Variable auf false gesetzt werden.
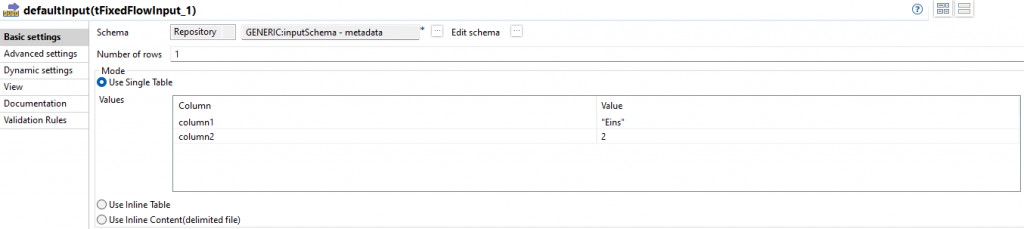
Der Default Input ist eine Row mit dem Schema inputSchema. Sie wird mit Hilfe eines tFixedFlowInput erzeugt.
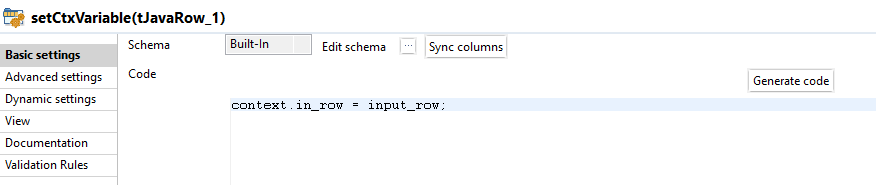
Die Context Variable in_row wird mittels tJavaRow gesetzt.
Der Default Output ist eine Row mit dem Schema outputSchema. Sie wird analog zum Input behandelt.


Processing

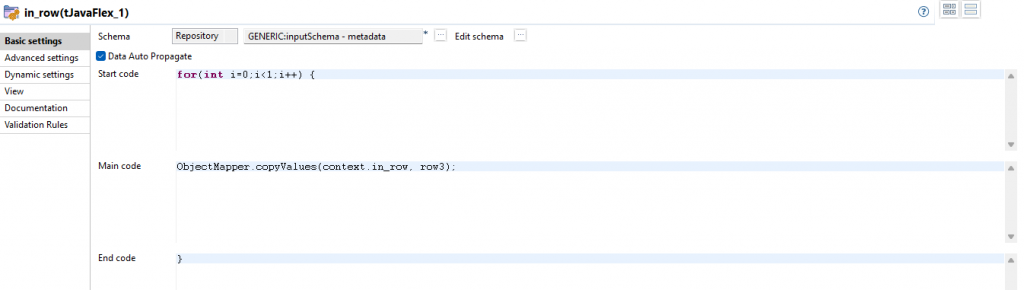
Die Verarbeitung beginnt mit einem tJavaFlex, welches als Startelement eine Schleife für die eine Input Row erzeugt und das Schema inputSchema hat. Dabei wird mit Hilfe des ObjectMapper die Context Variable in_row in die Ausgangsrow kopiert.
Die Transformation zum Outputschema erfolgt in der tMap Komponente, wobei die Werte der 2 Columns des inputSchema einfach konkateniert werden.
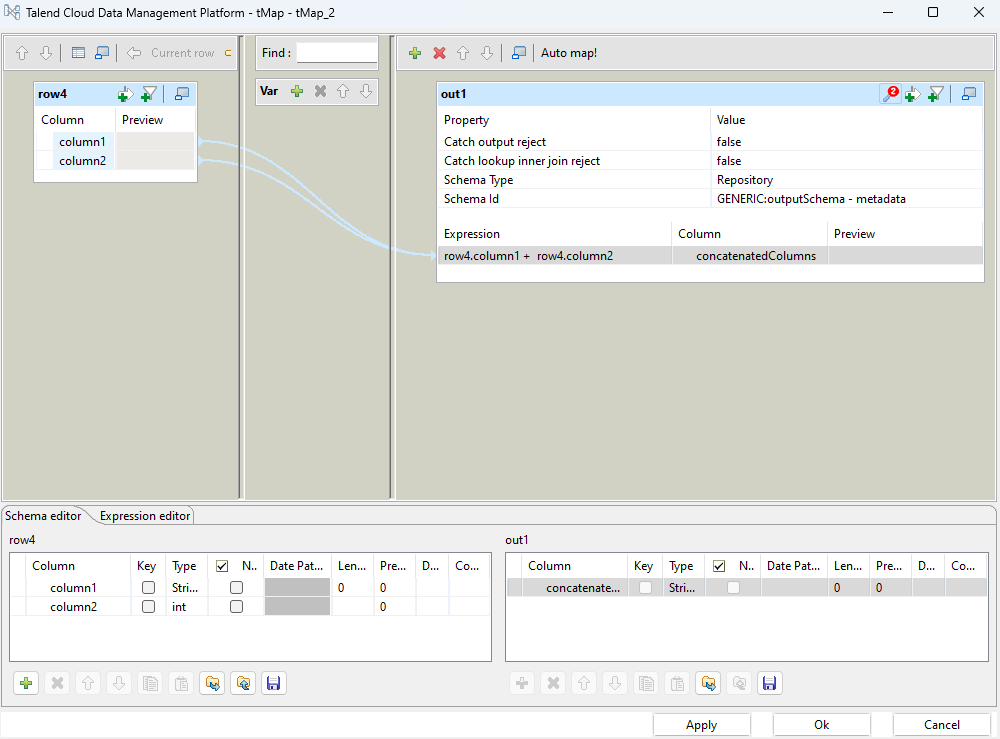
Mit Hilfe eine weiteren tJavaRow Komponente wird die verarbeitete Row in die Context Variable out_row kopiert.

Wiederverwendung mit tJob Komponente
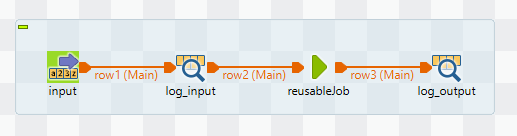
Im Beispiel wird ähnlich wie bei den Default Werten ein tFixedFlowInput verwendet, um eine Row zu erzeugen, die das Schema inputSchema hat.
Bei der tJob Komponente wird als Schema outputSchema angegeben. Die Parameter in_row und out_row werden mit den Variablennamen der Eingangsrow und Ausgangsrow besetzt.
Wichtig: Der Parameter standalone muss auf false gesetzt werden.